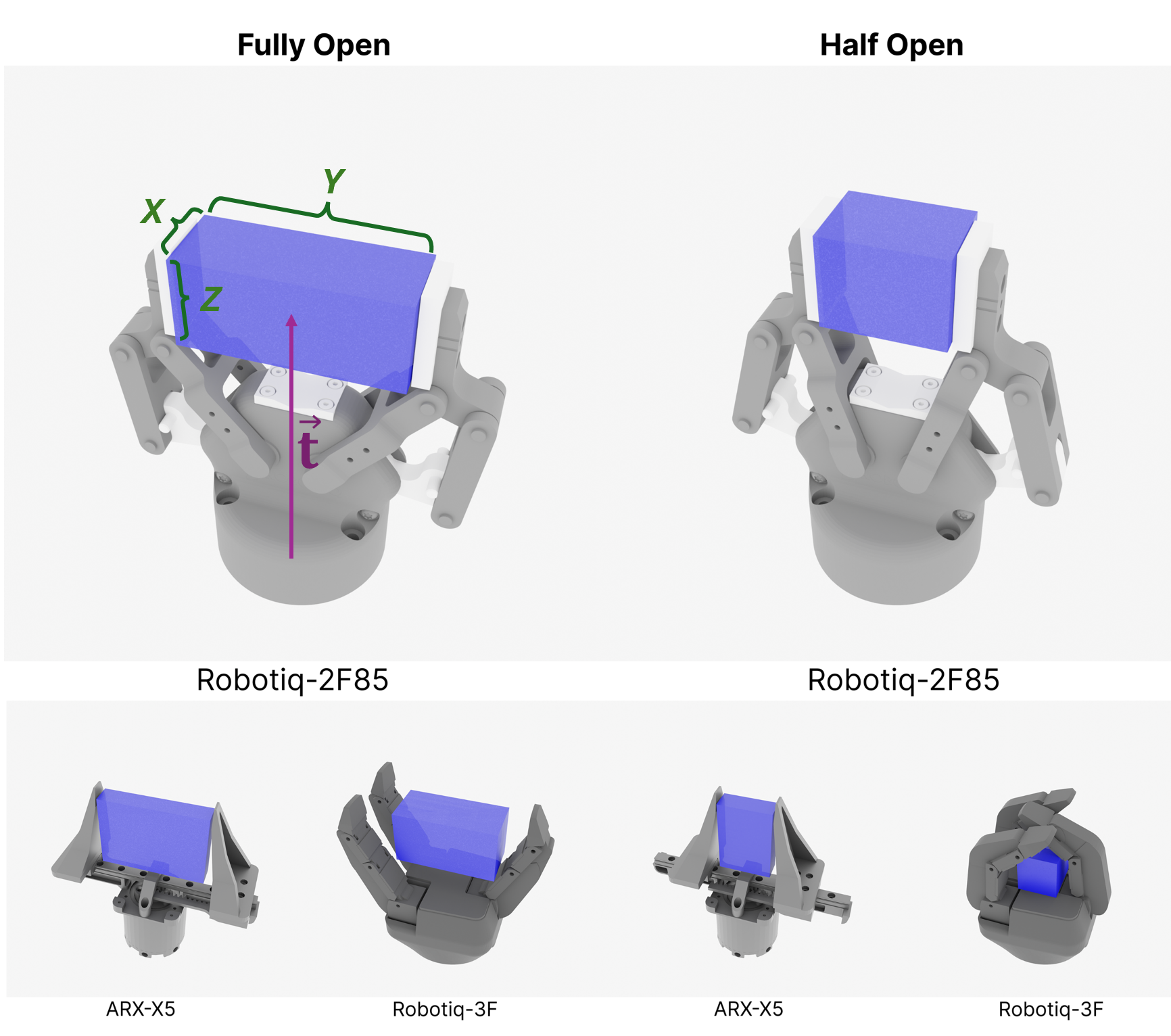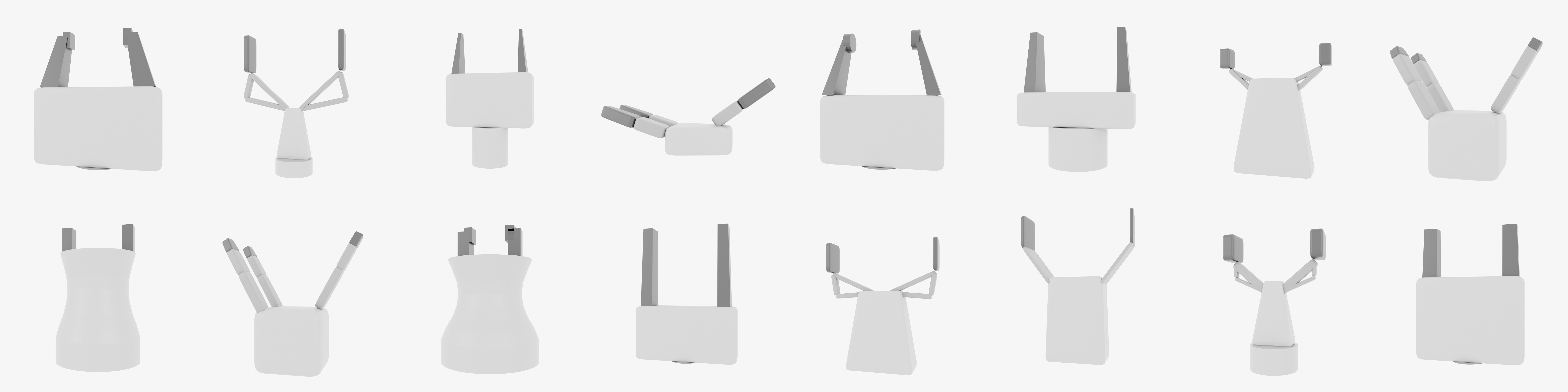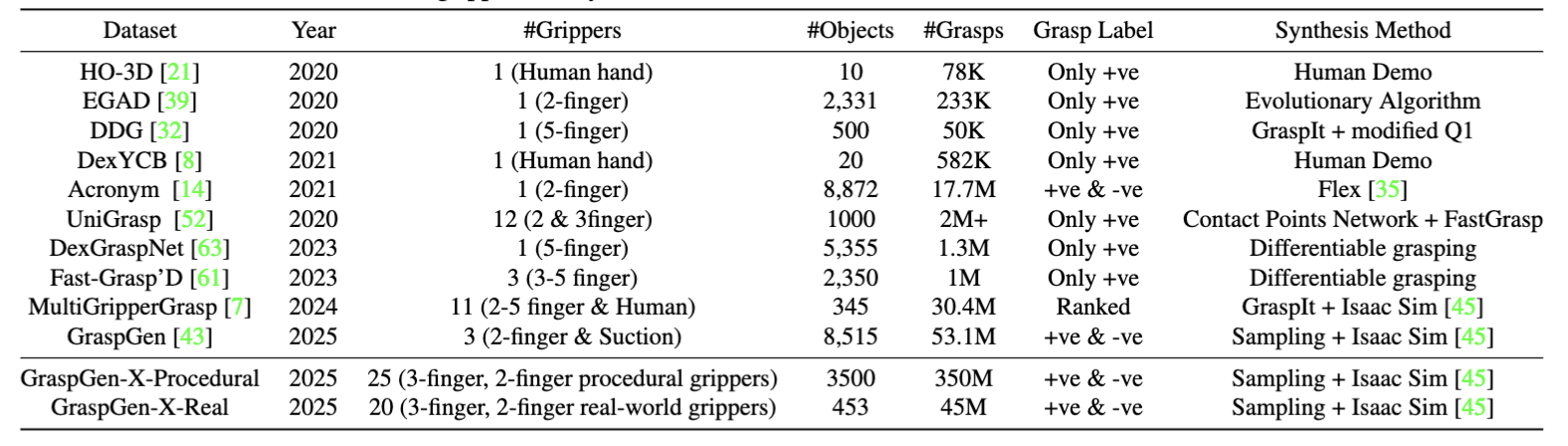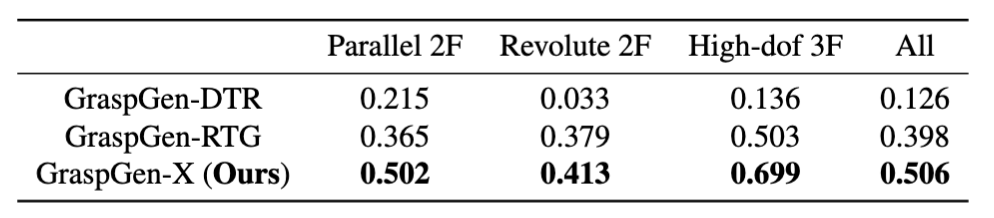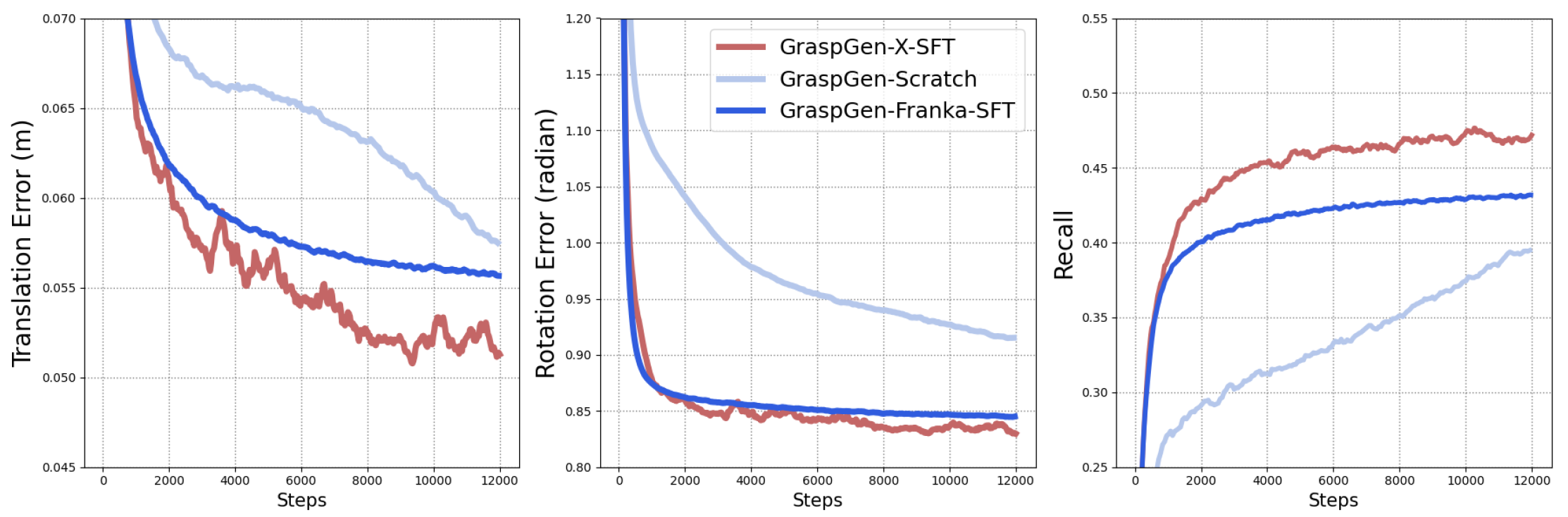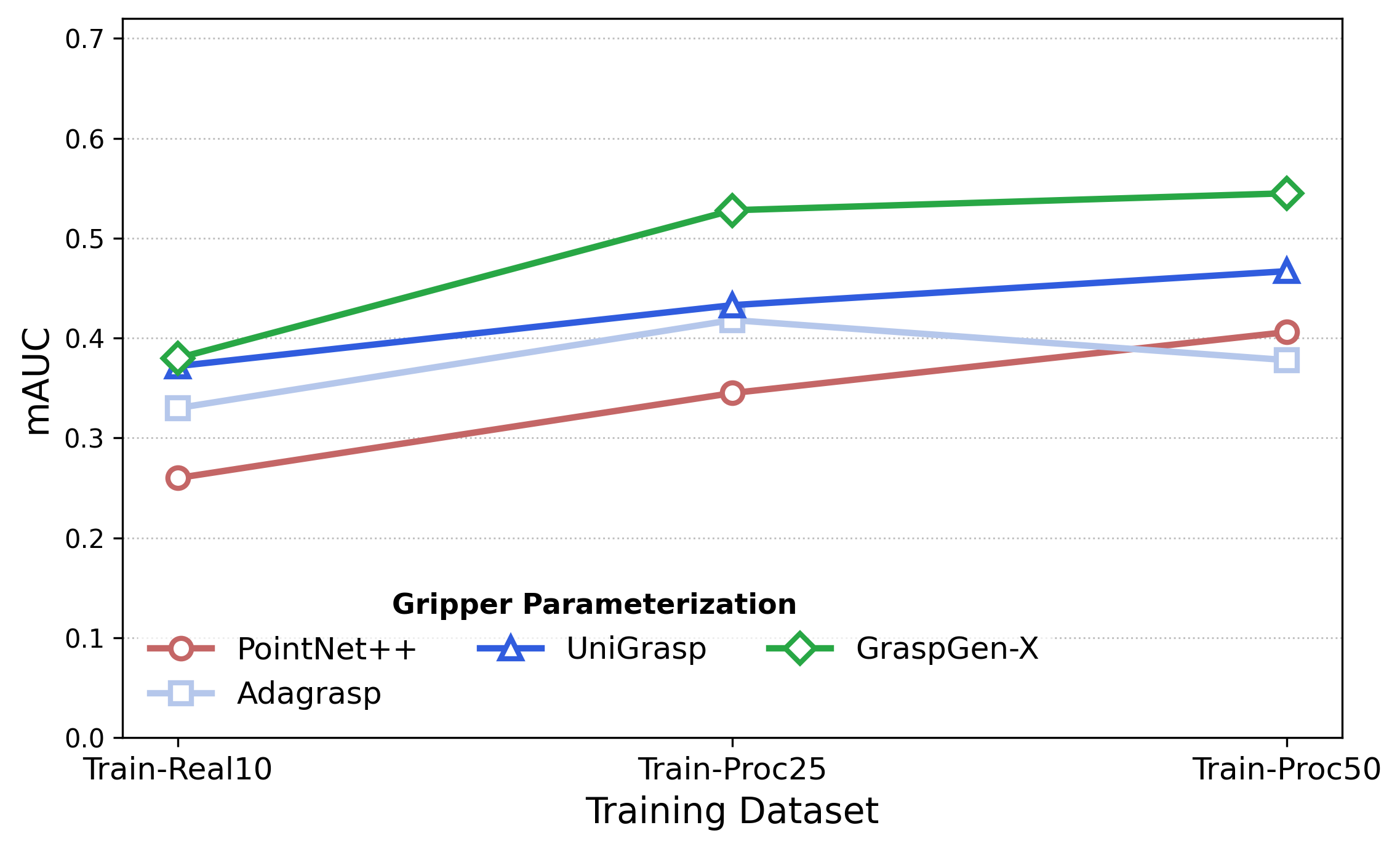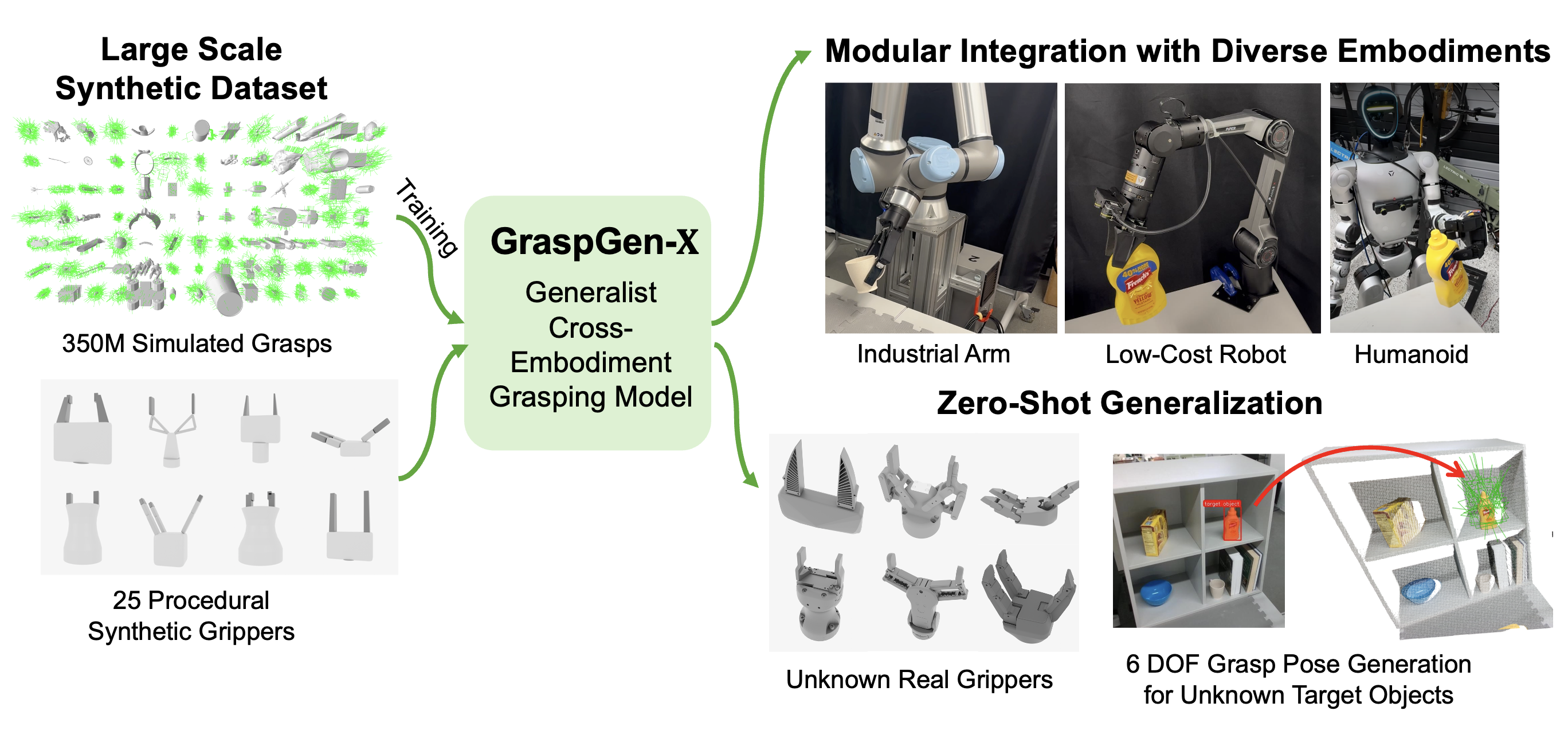
Swept-Volume Gripper Representation
We encode gripper geometry using a swept-volume heuristic — the union of volumes swept by the gripper during its closing motion. This compact representation captures the key aspect of the physical grasping process, which enables efficient zero-shot generalization to novel gripper morphologies.